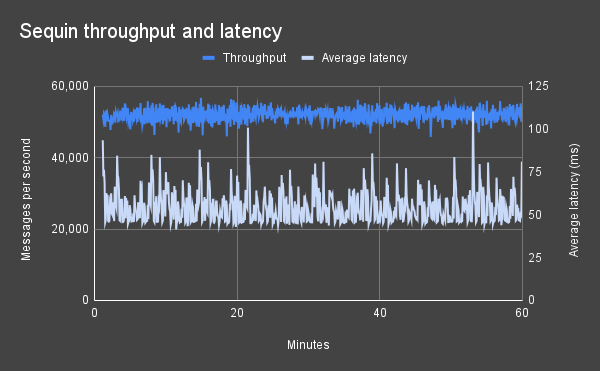
Sequin performance
Single‑slot peak throughput & latency
Sequin streams from a single Postgres replication slot to Kafka at:- 50k ops/s or 40 MB/s (whichever comes first), sustained
- 55ms average latency
- 253ms 99th‑percentile latency
Sequin on different instance sizes
Here’s a sampling of throughput Sequin can handle on different instance types:Debezium on MSK Connect (AWS)
Best if: you already run Amazon MSK and want a managed Kafka Connect runtime. The highest throughput we were able to consistently achieve with Debezium deployed on AWS MSK Connect was 6k ops/sec.
At this throughput, Sequin in a comparable setup has a latency that is significantly lower:
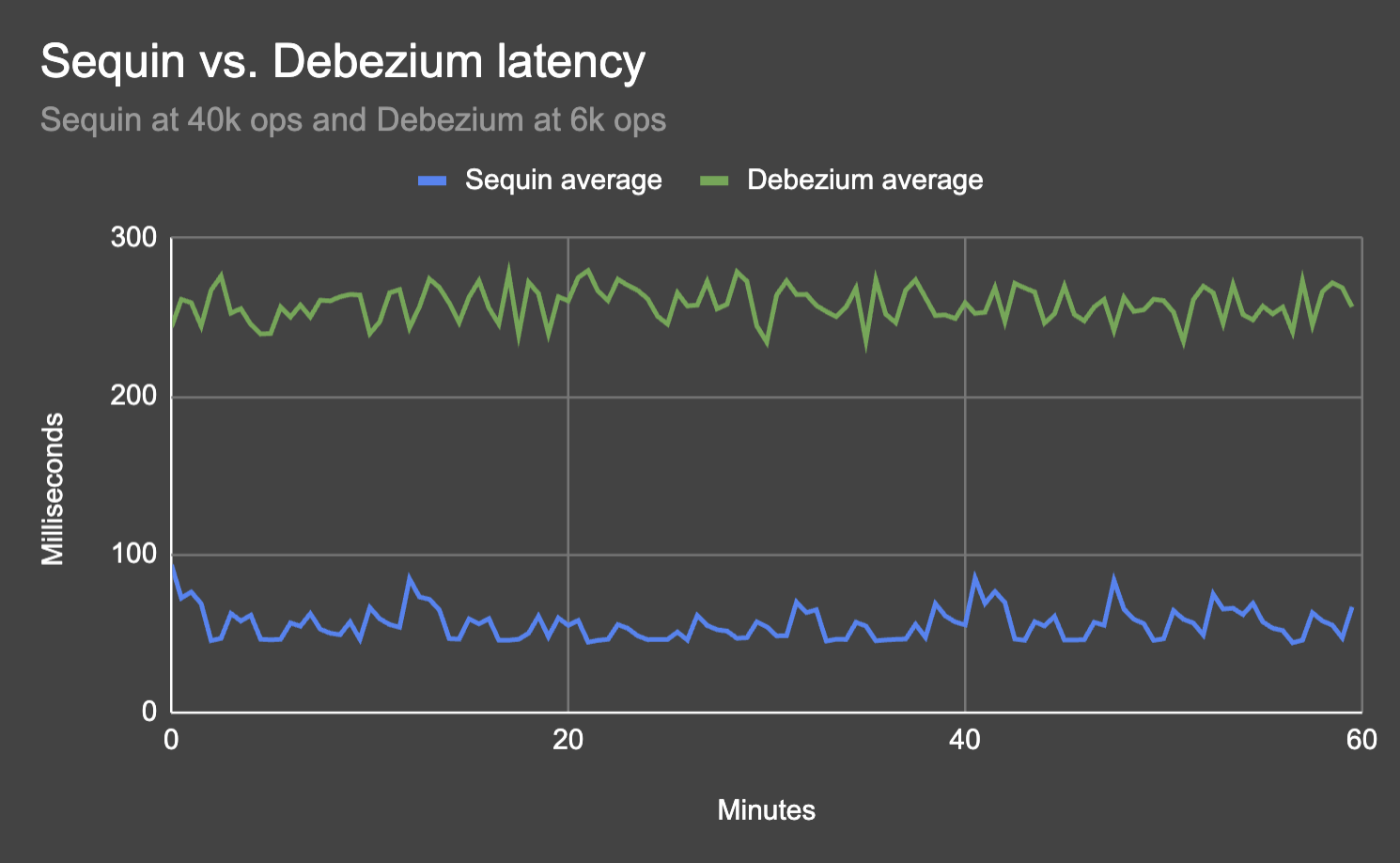
Scaling limits
- 8 MCUs (8 vCPU / 32 GiB RAM) is the hard ceiling MSK Connect exposes for a single connector.
- The connector is single‑threaded for snapshotting and heavily synchronized during streaming, so adding more MCUs has diminishing returns past ~4 MCUs.
Debezium Server (stand‑alone)
Best if: you need a minimal footprint and do not want to run full Kafka Connect.Debezium on Confluent Cloud
(Coming soon)Comparative benchmarks coming soon. Upvote the issue if you want to see them.
Debezium on self‑hosted Kafka Connect
(Coming soon)Comparative benchmarks coming soon. Upvote the issue if you want to see them.
Benchmark methodology
All of our benchmarks are open source and available on GitHub.
workload_generator.py deployed to a dedicated EC2 instance.
Throughput and end-to-end latency are measured with a Kafka consumer deployed to a separate EC2 instance. The stats are calculated as:
- Throughput: the number of records delivered to Kafka per second.
- Latency: the time between a change occuring in Postgres (
updated_attimestamp) and it’s delivery to AWS MSK Kafka (Kafkacreationtimestamp).
Workload
workload_generator.py applies a mixed workload of INSERT, UPDATE, and DELETE operations to the benchmark_records table.
benchmark_records Postgres table has the following schema:
Stats collection
Similarly, thecdc_stats.py script is deployed to a separate EC2 instance and reads from AWS MSK Kafka. Stats are bucketed and saved to a CSV file for analysis.

Infrastructure
Sequin, Debezium, and the rest of the infrastructure are deployed to AWS in the following configuration:- AWS RDS Postgres
db.m5.8xlargeinstance (32 vCPUs, 128GB RAM) - AWS MSK Kafka provisioned with 4 brokers
- AWS EC2 instances with Sequin running in Docker.
Summary
Sequin sustains 6 × – 8 × more throughput than Debezium’s on MSK, and over 2x the throughput of Debezium Server.
Next steps
Ready to see Sequin’s performance for yourself?What is Sequin?
Learn about Sequin’s architecture and how it works.
Quickstart with Kafka
Get started with Sequin CDC and Kafka in minutes.
Compare CDC Tools
See how Sequin stacks up against other CDC solutions.
Deploy to Production
Learn how to deploy Sequin in your production environment.